We keep hearing about this phrase, goodness of fit, sometimes hyphenated. But I never pause to think about that it is. I just search my papers, where I have several (close to 10!) statistical ebooks and none of them mentioned anything about it. Oh well. Wiki it is. Btw what would you do? ChatGPT? I wish I could fix the comment part of my blog…
OK, here is what Wiki says about goodness of fit.
“The goodness of fit of a statistical model describes how well it fits a set of observations. Measures of goodness of fit typically summarize the discrepancy between observed values and the values expected under the model in question. Such measures can be used in statistical hypothesis testing, e.g. to test for normality of residuals, to test whether two samples are drawn from identical distributions (see Kolmogorov–Smirnov test), or whether outcome frequencies follow a specified distribution (see Pearson’s chi-square test). In the analysis of variance, one of the components into which the variance is partitioned may be a lack-of-fit sum of squares.”
So to paraphrase, the goodness of fit is a way to evaluate statistical models, and it focuses on how well the model (expectations) fits the observations. For example, R2 is a goodness-of-fit measure. This led me to think what other ways of evaluating statistical models could be. Recalling the steps we take after constructing a linear model, there are diagnostic tests (residual checks), model comparison, significance of coefficients, etc. Here is a summary table from ChatGPT:
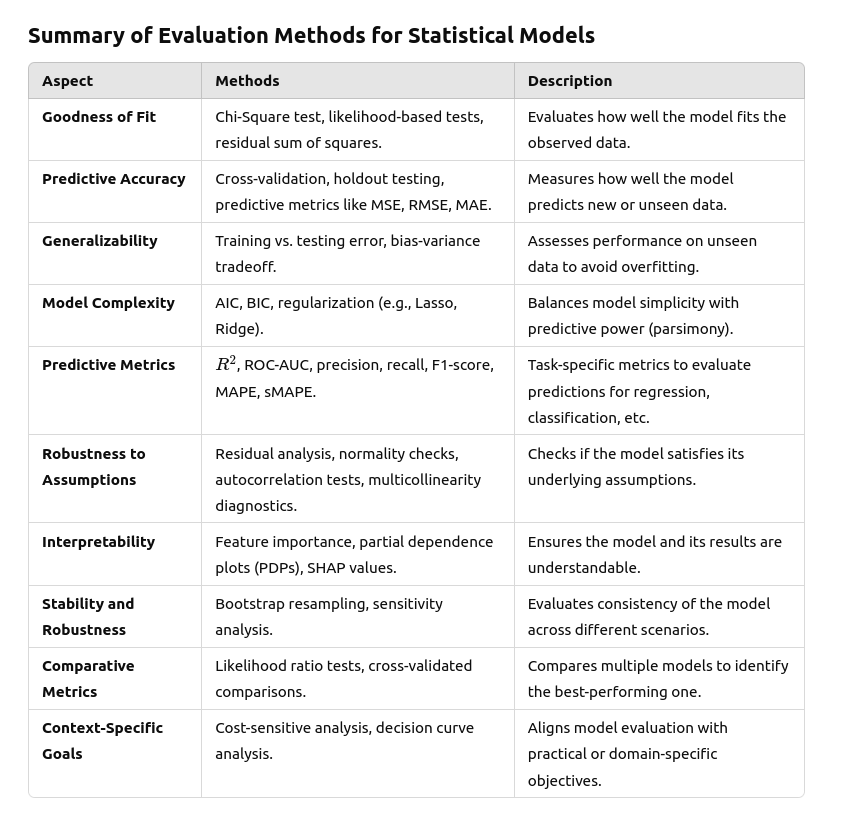
However, as you can see, nothing was mentioned about the significance of coefficients. When I ask chatGPT, it says: “Testing whether a coefficient in a linear regression model is significant is not typically classified as a type of model evaluation. Instead, it is considered part of inference or hypothesis testing about the relationships between variables in the model.” Oh my. Inference.
Brian’s understand of inference
When I was taking JHU’s Data Science Specialization on Coursera, one of the course is Statistical inference. It happens after Reproducible Research and before Regression Models. In the beginning of the course, Brian Caffo defined it as the process of drawing formal conclusions from data., which is further defined as settings where one wants to infer facts about a population using noisy statistical data where uncertainty must be accounted for. Not very conclusive. Later in the course we talked about probability, conditional probability, expectations, variance, common distributions, asymptopia (law of large numbers and central limit thereom), t confidence intervals, hypothesis testing, pValues, power, multiple testing and resampling. So some basic statistical concepts.
Kyle’s understand of inference.
In Kyle’s advanced statistics course where I co-teach, he did mention about inference and back then I did pause to contemplate on this word. On the slide for Inference he says:
- How to evaluate whether our model fits the data well? This includes goodness-of-fit measure such as R2 and diagnostic tests that evaluates residuals.
- How to evaluate whether all our predictors are useful for the model? This includes t-tests or ANOVA that evaluates model parameters. This is usually referred to as hypothesis testing, where we assumes the
Wiki’s inference
When I looked on Wiki, statistical inference is mentioned as opposed to descriptive statistics, which mainly includes “measures of central tendency and measures of variability or dispersion. Measures of central tendency include the mean, median and mode, while measures of variability include the standard deviation (or variance), the minimum and maximum values of the variables, kurtosis and skewness”.
“Statistical inference is the process of using data analysis to infer properties of an underlying probability distribution.[1] Inferential statistical analysis infers properties of a population, for example by testing hypotheses and deriving estimates. It is assumed that the observed data set is sampled from a larger population. “
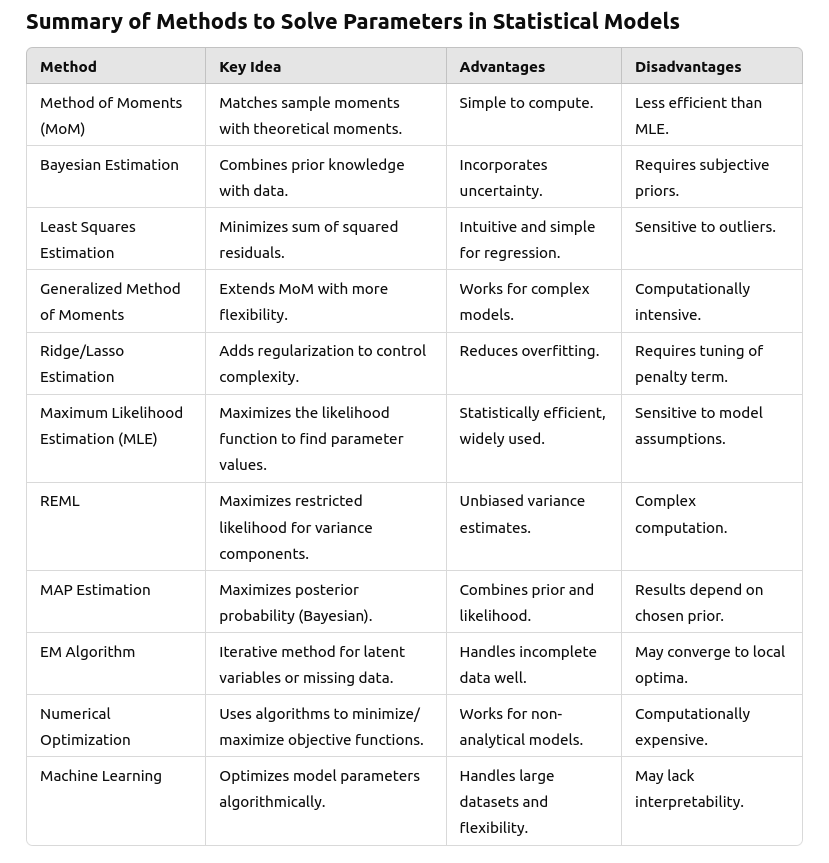
Before we can evaluate whether the predictors are useful for the model, we need to first find/solve the parameters/coefficients. How parameters are found in models? I can think of four:
- LSE: least squares estimation
- MLE: maximum likelihood estimation
- Bayesian: summarizing the posterior
- Loss function: machine learning.
Then I asked ChatGPT to give me a more comprehensive table:
Andrej’s understanding of inference.